

فى الشبتر ده يا جماعة هنعرف ان شاء الله العناصر الاساسية المكونة لجهاز المحمول وطبعا العناصر الى تهم الاتصالات
وهنعرف اية الى بيحصل فى الاشارة من اول دخولها كأشارة صوتية الى وصولها الى الشبكة ثم الى المستقبل
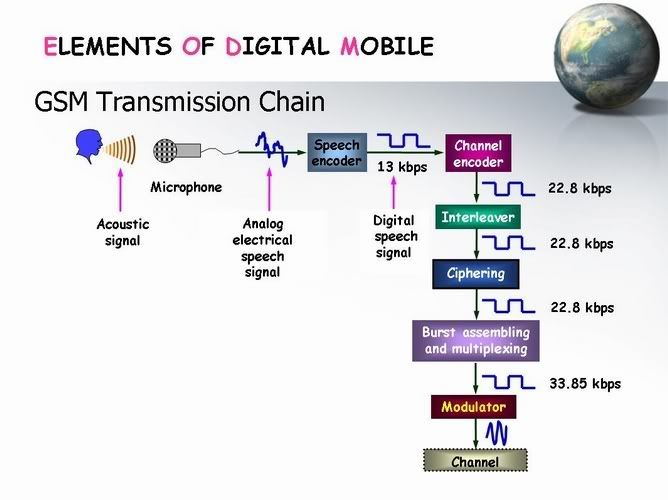
زى محنا شايفين فى الصورة الى فاتت دى . دى المراحل الى بتمر بيها الاشارة من اول مهية اشارة صوتية لغاية لما تتبعت فى الهواء
همتكلم عنها بسرعة كدة ونقول وظيفة كل جزء من الاجزاء دى وبعدين نتكلم عنهم بالتفصيل
طبعا احنا شايفين الاخ الى بيتكلم ده لما بيتكلم الاحبال الصوتية بتاعته بتعمل تضاغطات وتخلخلات فى الهواء فينتج عنها الصوت بتاعنا ده يعنى اشارة صوتية Acoustic Signal
الاشارة الصوتية دى بتدخل على الميك بتاع الموبيل . الميك دة يحول الاشارة الصوتية دى الى اشارة كهربية
Analog Electrical Speech Signal
طبعا احنا بنتعامل مع اشارة Digital مش Analog
يبقى احنا محتاجين حاجة تحول الاشارة بتاعتنا دى الى اشارة Digital
علشان كدة هندخلها على ال Speech Encoder الى هيحولها الى اشارة Digital
وهيقطعها وهيضغطها وهتخرج منه اشارة ال Bit Rate بتاعها 13 kb/sec
وهنقول لية ...
بعد كدة هتدخل على ال Channel Encoder
هو ده الى بيضيف ال Redundence Bits وبكدة يبقى ال Bite Rate بتاعنا 22.8 kb/sec
بعد كدة هتدخل على ال Interleaver الى بيعمل تشتيت وتفريق لل Burst علشان نقدر نعمل ال
Error Detection And Correction الى هو تصحيح الاشارة
بعد كدة هتدخل على ال Ciphering عملية التشفير
بعد كدة على ال Burst Assembling And Multiplexing
الى بيضيف ال Tail Bits وال Hide Bits وال Stealing Flags
وطبعا بعد الاضافات ال Bits دول الاشارة هتبقى ب Bit Rate يساوى 33.85 kb/sec
بكدة تكون الاشارة بتاعتنا جاهزة للأرسال يعنى مش فاضل الا عملية التحميل Modulation
والارسال
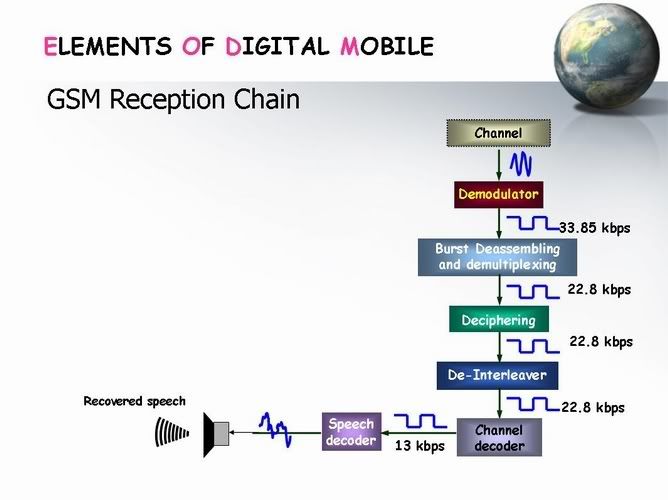
طبعا وزى ماهو فى اى نظام ارسال واستقبال هنحتاج نعكس الاجراءت الى احنا عملناها فى الاشارة فى الارسال علشان نوصل للاشارة الصوتية نفسها الى تم ارسالها ...
تعالوا بقى نتكلم عن المراحل دى مرحلة مرحلة وبالتفصيل

Speech Encoder - 1
احنا قولنا انه بيعمل تلت عمليات . بس تعالوا الاول نشوف اية الخصائص الى احنا هنحتاجها فى ال
Speech Encoder الاول
اول حاجة لازم يكون بيخرج الاشارة ب Bit Rate قليل يعنى تكون مضغوطة بشكل كويس علشان احنا زى محنا شايفين عندنا شكلة فى اعداد ال Channels فطبعا احنا مش ناقصين كمان ان الاشارة تكون كبيرة ومحتاجة Band
Width كبير
تانى حاجة انه يكون بيخرج الاشارة بجودة محترمة ومش معنى انى عاوز اضغطها انها تيوظ
تالت حاجة ان يكون تكلفته مش عالية اوى علشان ده هيبقى موجود فى الموبيل وبالتالى الناس هتشتريه وبالتالى لازم يكون سعره معقول..
فى جملة مكتوبة تحت كدة انتوا اكيد شايفينها .. حد فاهمها ؟؟؟؟؟
الجملة دى بتقول ان ال GSM بيرسل معلومات عن الصوت مش بيرسل الصوت نفسه ..والموضوع ده ان شاء الله هنشرحه بالتفصيل...
احنا قولنا ان ال Speech Encoder ده بيعمل تلت حاجات اول حاجة هى التحويل من Analog الى Digital
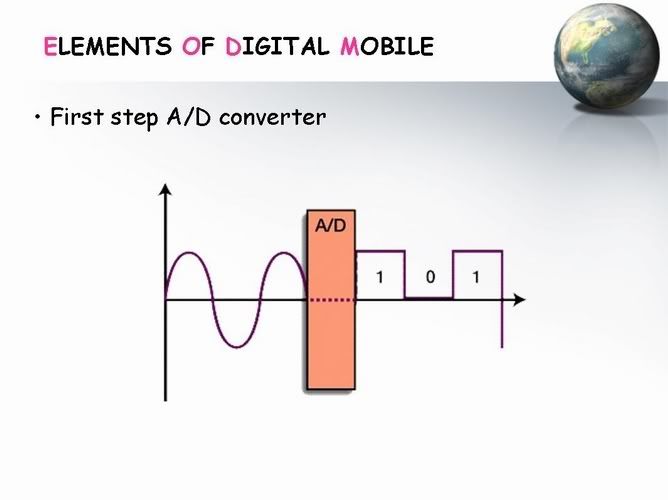
احنا هنا فى ال GSM بنستخدم ال Pulse Code Modulation علشان نحول .
وال PCM ده ليه اربع خطوات هنتكلم عنهم بسرعة علشان طبعا احنا كلا خدناهم قبل كدة احنا هنذكر بيهم بس
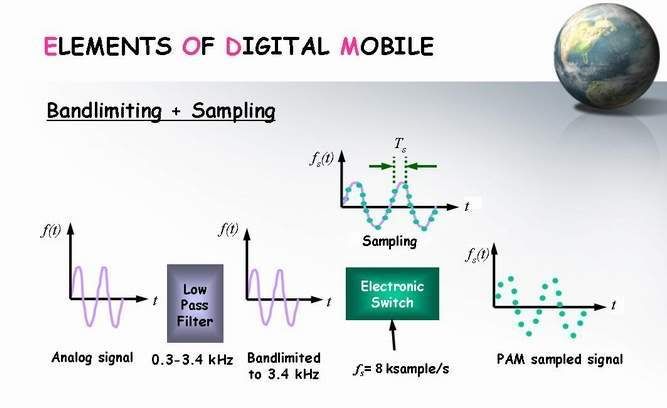
الخطوة الاولى Bandlimiting
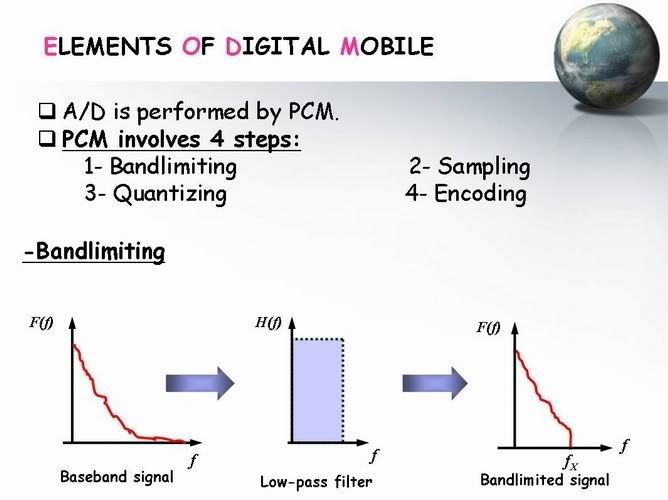
ودى بكل بساطة يعنى بنعدى ال الاشارة بتاعتنا على Low Pass Filter
وده علشان يشيل شوية الترددات الى ملهاش لازمة وبكدة كون قللنا ال B W
شوية
الخطوة الثانية Sampling
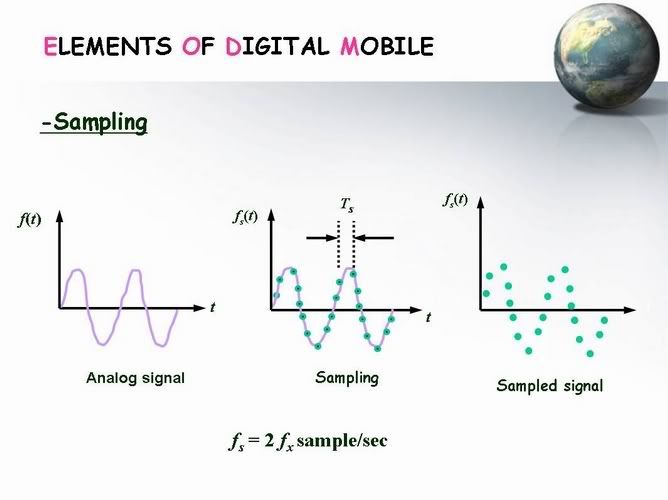
فى المرحلة دى بنمرر الاشارة على Electronic Switch
بتردد 8 khz فى الثانية معنى كدة اننا هنحصل على 8000 sample / sec
وده لان فى قانون بيقولى انى علشان اعمل sampling لاى اشارة لازم يكون تردد السويتش اكبر من او يساوى ضعف تردد الاشارة
والاشارة بتاعتنا هنا بقى هى الصوت الى تردده 3.4 khz يعنى لازم تردد السويتش يساوى 6.8 khz على الاقل
احنا بقى هنستخدم سويتش بتردد 8 khz
الخطوة الثالثة Quantizing
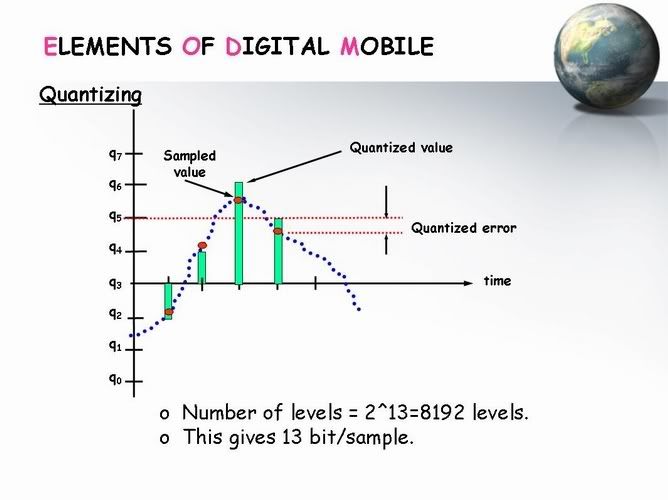
بعد عملية ال Sampling هنلاقى ان القيم الناتجة عندى قيم كتير اوى وعلشان كدة هعمل تقريب للقيم دى لاقرب ليفل محدد . وطبعا ده هينتج عنه مشكلة فى الاشارة والحل انى ازود عدد ال Levels بس مش هيبقوا كتير اوى والا هنكون معملناش حاجة ... علشان كدة هخليها 2 اس 23 يعى هتساوى 8192 Levels
وده هيدينا 13 bits /sec
الخطوة الرابعة Encoding
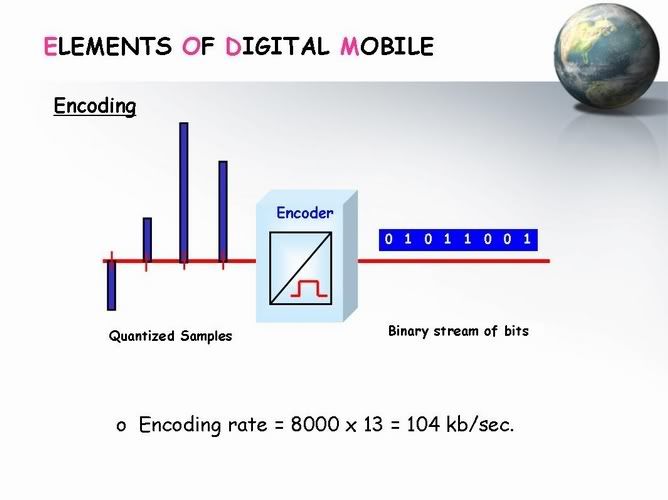
بعد عملية ال Quantizing احنا بقى عندنا مجموعة من ال Levels هى الى بتعبر عن الاشارة
كل Level منهم بنعبر بيه ب مجموعة من ال bits
علشان كدة احا هدخل الاشارة بتاعتا على ال Encoder علشان يحولها الى مجموعة م ال bits
وال Rate بتاعة هيبقى 104 kb/sec
نيجى لتانى حاجة بيعملها ال Speech Encoder وهى ال Segmentation
اخنا كدة خلاص يا جماعة وصلنا اننا حولنا الاشارة الى مجموعة كبير من ال bits
طيب وبعدين طبعا مش هينفع بعتهم كدة لان انا عندى B.W محدود الى هو ال TS
يبقى لازم اقطع المجموعة دى الى مجموعات
طيب هو انا هقطعهم ازاى واية الى هيحكمنى فى عملية التقطيع .
بصوا يا جماعة احنا لينا احبال صوتية ليها تردد معين زى محنا عارفين طيب .
احبالنا الصوتية معندهاش القدرة على التغيير فى التردد ده بسرعة كبيرة .
يعنى على سبيل المثالواحنا بنتكلم لو خرج تردد مقداره 1.4 khz
هيفضل هو نفس التردد لمدة 20 msec
وبعد كدة تقدر احبالا الصوتية تغييره الى تردد اخر .
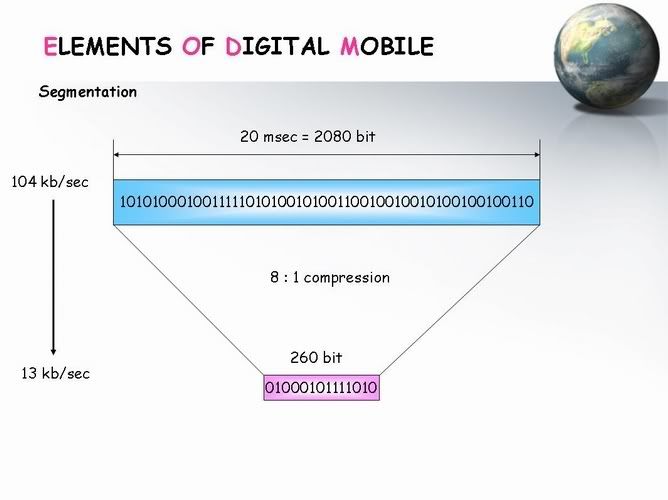
يبقى احنا هنقطع الاشارة بتاعتنا الى مجموعات الزمن بتاع كل مجموعة هو 20 msec
ولما شوفنا كل 20 msec فيها كام bit لقيناهم 2080 bit
وده لان احنا قولا ا ال rate بتاعنا هو 104 kb/sec
يعنى لو عاوزين عرف ال rate فى 20 msec هتيقى سهلة مش كدة.
ال 2080 bits دول هما عبارة عن ال Frame بتاعنا وطبعا احنا قولنا قبل كدة ان احنا بقسم ال Frame ده الى
8 TS يبقى احنا محتاجين نضغط ال 2080 bits دول فى TS يعنى محتاجين نضغطهم بسبة 1 الى 8
وبكدة هيبقوا 260 bits فى كل TS
Predictive Coding
بصوا يا جماعة
واحنا بتكلم فى الموبيل مش بنتكلم علطول طبعا احنا بتكلم ونستنى الرد ونرد ونستنى الرد وهكذا
معنى كدة ان المرسل بيبعت المعلومة ويفضل شغال على الفاضى مش كدة .
وطبعا ده مش منطقى علشان كدة عملنا ال Predictive Coding ده
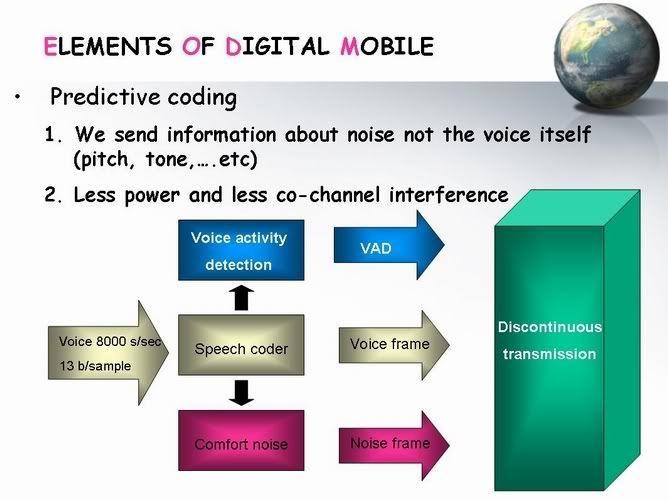
بعد خروج الاشارة م ال Speech Coder بتروح لل Predictive Coding
بتروح مها عينة لل Voice Activity Detection VAD
وده بيخرج اشارته الى ال Discontinuous Transmission DTX
يقول لل DTX الاشارة دى عبارة عن كلام ولا Noise
طيب وهو ال VAD ده بيعرف ازاى اصلا ان الاشارة الى جاية دى بتحتوى على كلام ولا لا
ايوة تمام . عن طريق التردد لان زى محنا عارفين ان تردد صوت الانسان فى الحيز من 0 الى 3.4 KHZ
المهم اول لما ال DTX يعرف انها اشارة تحتوى على صوت يقوم بتشغيل المرسل
ولو الاشارة الى جاياله من ال VID بتقوله ان الاشارة عبارة عن Noise وال Noise الى احنا قصدنا عليها هنا هى عبارة عن الفراغ او اى صوت مش فى الحيز بتاع الكلام
طيب ولو الاشارة الى جاية لل DTX من ال VID بتقوله ان الاشارة بتاعتنا عبارة عن Noise هنا سيقوم ال DTX بأغلاق ال TX وهنا هنلاقى اننا قمنا بالحد م استهلاك البطارية وكمان هنحد من ال Co - Channel Interference مش كدة .
طيب وهو لو احنا قفلنا ال TX الراجل الى معايا على التليفون ده مش هيسمع حاجة خالص ولا اية الى هيحصل
فى الحالة دى الموبيل هيعمل حاجة حلوة اوى .
اول ال DTX ميحس ان الصوت او الكلام وقف هيوقف المرسل وهياخد الاشارة الى جاياله من ال
Silence Descriptor SID
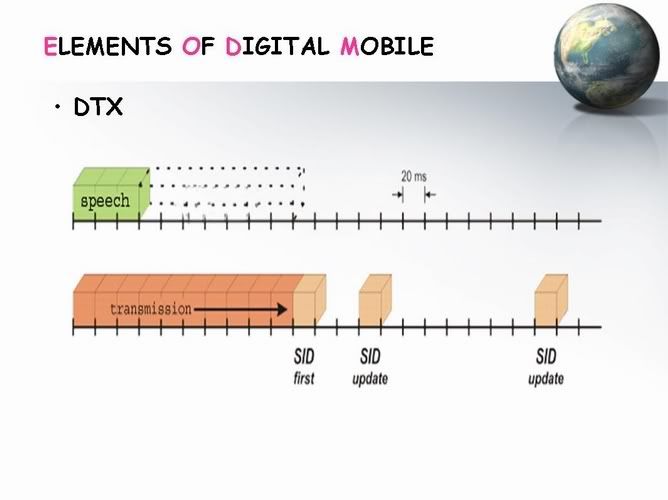
تتولد ال SID Frame فى المرسل من القياس المستمر لخلفية المعلومة الصوتية (Noise ) . ويرسل هذا ال Frame بعد الكلام مباشرة وفى بداية توقف الكلام يتعرف المستقبل على نهاية الكلام ويقوم بتفعيل خاصية ال Comfort Noise
ولكن بالمعلومات التى قد تم ارسالها عن ةطريق ال SID Frame فى المرسل بتاع الموبيل الاخر
والى عبارة عن تسجيل لاخر Noise بعد كدة بيقوم ال SID بعمل Update لل Noise يعنى بعد فترة معينة يقوم ال SIDبتسجيل لل Noise ويبعتها لل DTX الى بيقوم بأرسالها ويسكت شوية وبعدين يقوم ال SID بتسجيل لل Noise ويبعتها لل DTX وهكذا
ليست هناك تعليقات:
إرسال تعليق